目录
[TOC]
前言
Raft是一种更易理解的一致性算法(Distributed Consensus). Raft已经在各种语言中得到实现.
Raft is a protocol for implementing distributed consensus
什么是分布式一致性?
单节点环境 –> 多节点环境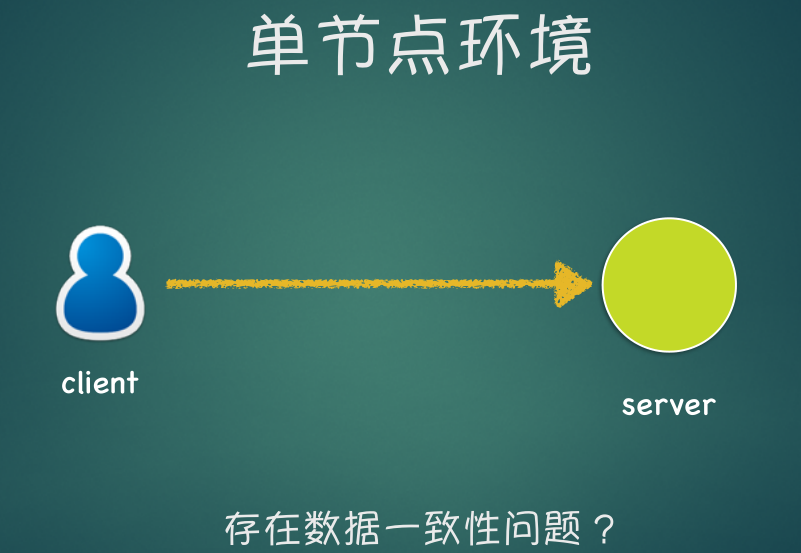

多节点环境下, 多个节点直接如何能保证数据的一致性?
Raft中的角色
Raft中有三种角色, 每一个节点任意时刻只处在某一个时刻, 初始状态下都处于:Follower角色状态下
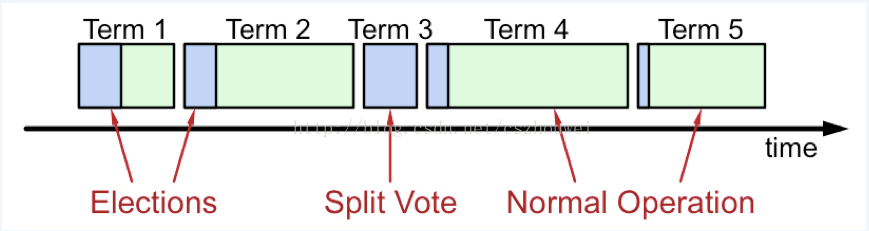
Terms
- 每个Term至多存在1个Leader
- 某些Term由于选举失败,不存在Leader
- 每个Server本地维护currentTerm
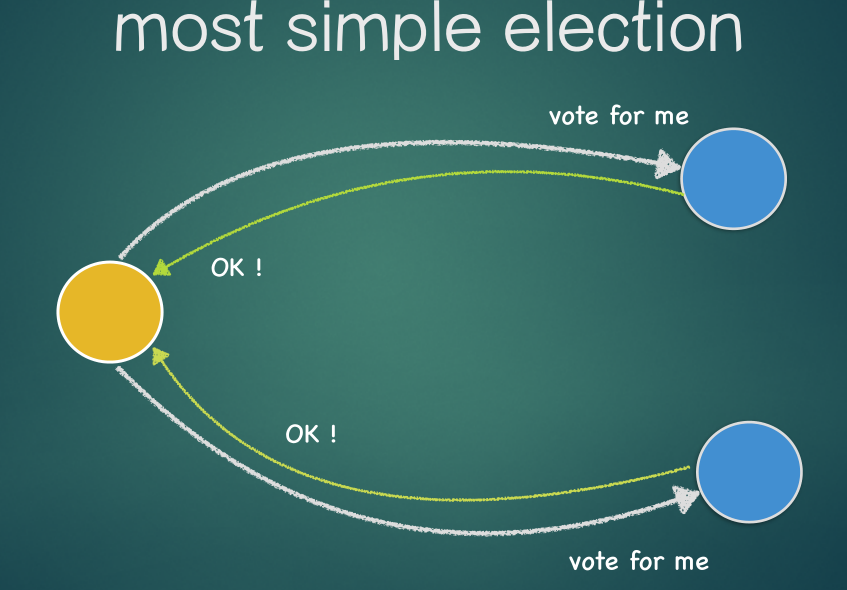
Leader Election(领导人选举)
Raft中使用的模式是只有一个领导者,整个系统中的改变都需要经过leader,选举过程如下:
- 如果一个follower没有收到leader的消息, 则这个follower变成一个candidate
- candidate 开始向其它的节点发送请求投自己一票
- 如果candidate收到了多半的选票, 它将成为leader
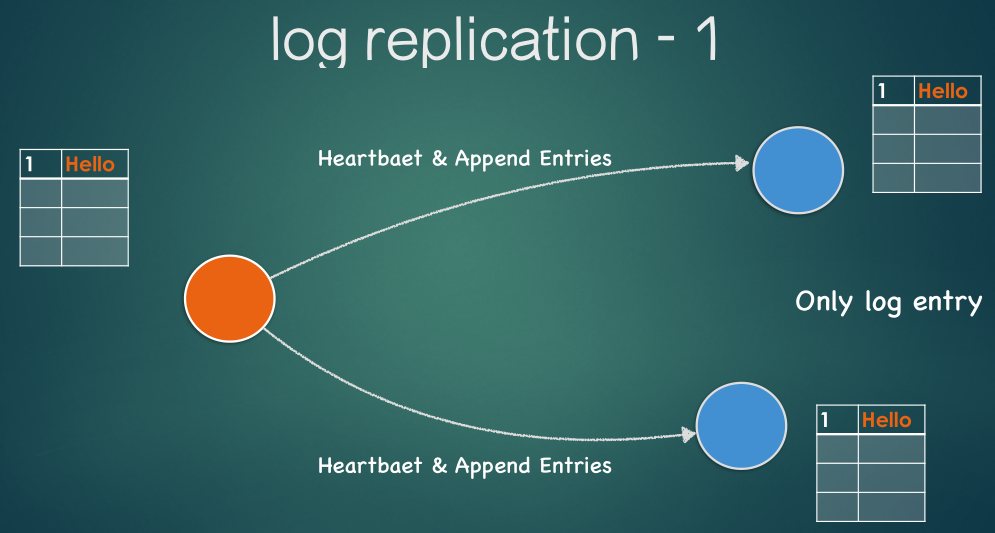
Log Replication(日志复制)
Raft中所有的改变都以日志的形式存放
- 客户端发送一个’SET 5’请求给了leader
- leader没有把这个请求记录提交, 所以并不会修改节点的值
- leader首先把这个log entry发送给follower nodes
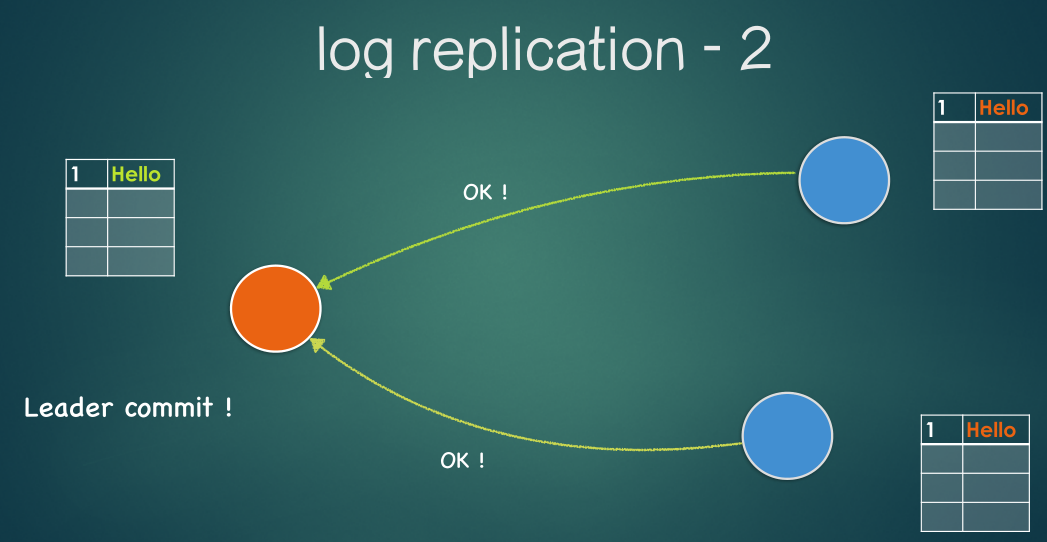
- leader等待多半的follower返回响应
- leader提交请求, 更新数据’SET 5’
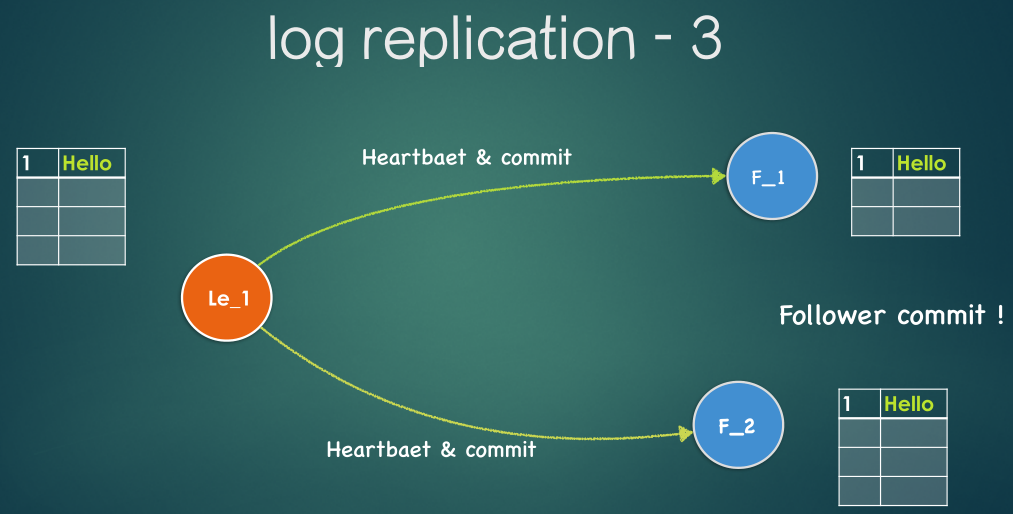
- leader通知所有的follower, 这个记录可以被提交了(follower上也更新数据)
- 最后整个cluster的数据是一致的
election timeout(选举超时)
选举超时是一个follower变成candidate的时间量, 是一个150ms-300ms的随机数.
- 最开始都是follower
- 生成一个election timeout, 比如: 200ms
- 等待200ms之后, follower变成选举者, 开始进入选举期
- 首先投票给自己
- 发送请求Request Vote给其它节点, 如果其它节点收到请求之后, 还没有投过票, 它就会把票投给这个候选者
- 候选者获得多半选票之后成为leader
heartbeat timeout(心跳超时)
默认: 50ms
当leader产生之后, 需要一直去心跳检测所有的follower是否是存活的状态
同时也保证follower能确保leader是正常工作的
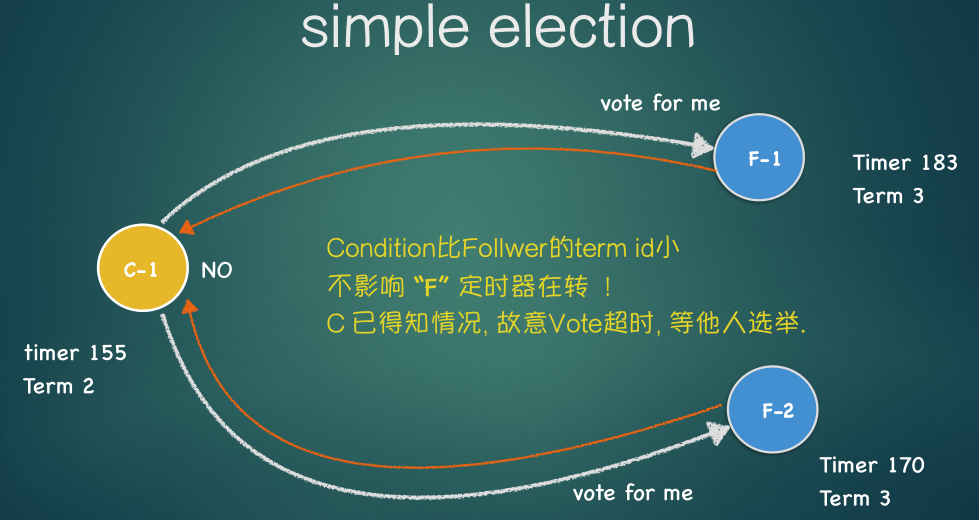
Split Vote(分裂投票)
如果同一时刻有两个candidate产生, 就会出现它们获取的票数一样的情况, 如法选举出leader
- 两个candidate出现, 发送给其它的node投票请求
- 这两个candidateu获取的票数一样,无法产生leader
- 这时候就需要重新一轮投票(在两个candidate中), 重新产生election timeout, 这个时候,再出现split vote的概念就非常低了
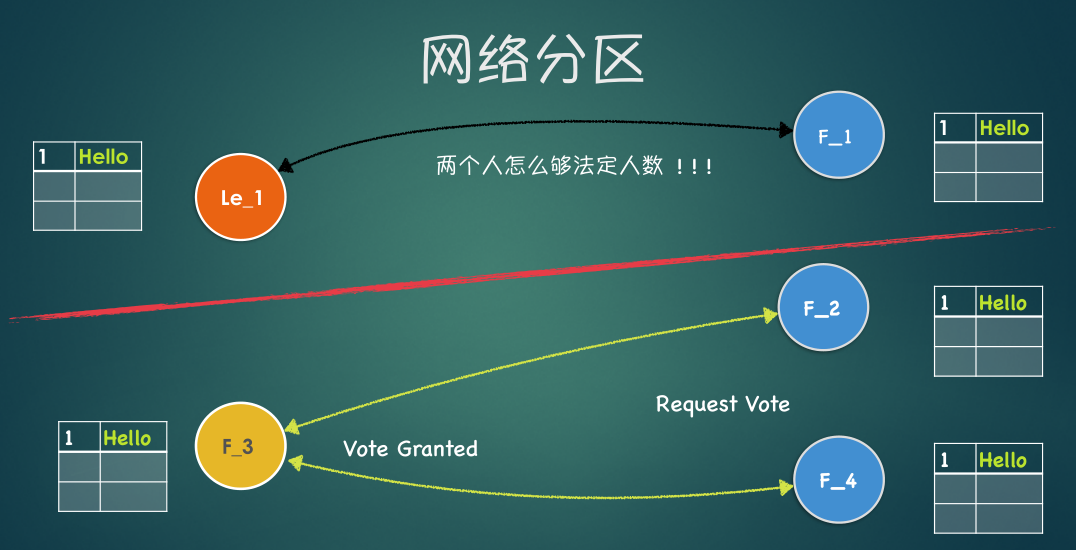
Network Partition(网络分区)
重新选举出现在:follower在heartbeat timeout期间没有收到来自leader的请求:
- leader确实挂掉了
- leader和follower不在一个网络分区中, leader和follower都没有挂掉
在这个情况下, follower会重新开始选举 - 这个时候会产生两个分区
- 每个分区都会有一个leader产生(这个时候两个term会不一样)
- 每个分区单独工作
- 当分区结束(网络恢复), term值更大的leader成为真正的leader, term值小的leader下台
- 日志回滚