前言
早会上同事分享了<<数据库的范式和反范式>>, 正好自己也正在设计数据库的几个表, 也加深了自己对范式的认识, 特记录分享出来
场景
我们给出一个表的设计, 里面填充了一些数据, 我们看看这个表会有什么问题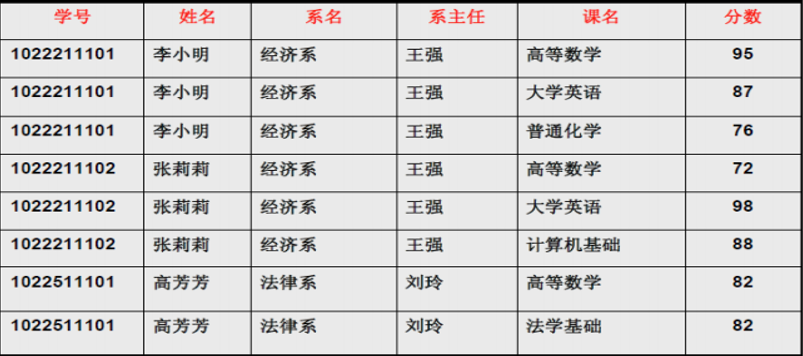
上面的表有几个问题:
- 数据冗余:每一名学生的学号、姓名、系名、系主任这些数据重复多次
- 插入异常:假如学校新建了一个系,但是暂时还没有招收任何学生(比如3月份就新建了,但要等到8月份才招生)
- 删除异常:假如将某个系中所有学生相关的记录都删除,那么所有系与系主任的数据也就随之消失了(一个系所有学生都没有了,并不表示这个系就没有了)
- 更新异常:系主任换了,我们需要把系里所有学生的行都给更新一遍,显然开销过大
什么是范式?
就是一张数据表的表结构所符合的某种设计标准的级别
遵循范式的好处?
- 减少数据库的冗余
- 消除异常(插入异常, 更新异常, 删除异常)
- 让数据组织更加和谐
范式有哪些?
- 第一范式(1NF)
- 第二范式(2NF)
- 第三范式(3NF)
- BC范式(BCNF)
- 第四范式(4NF)
从上到下要求越来越严格,一般在我们设计关系型数据库的时候,最多考虑到BCNF就够。符合高一级范式的设计,必定符合低一级范式,例如符合2NF的关系模式,必定符合1NF。
名词解释
- 码:一个表中,可以唯一决定一个元祖的属性“集合”。而主键则是可以唯一决定元祖的“某个属性”
例如:在成绩表中(学号,课程号)合起来叫一个码,而分开看学号是主键,课程号也是主键 - 非主属性:不属于码的属性
- 主属性: 属于码的属性
- 候选键:指每个都不一样、非空的属性,有着潜在的主键意义,比如一个表中的课程号、学号
第一范式
标准定义: 符合1NF的关系中的每个属性都不可再分
1NF是所有关系型数据库的最基本要求
上面的图很明显是一个excel的表, 在关系型数据库中是不会存在这种表的, 所以关系型数据库都符合第一范式
第二范式
标准定义: 符合1NF,并且,非主属性完全依赖于码
表中的每个非键字段由整个主键确定,且不能由主键自身的一部分确定
特殊: 根据定义知道若码只有一个属性, 则必定满足第二范式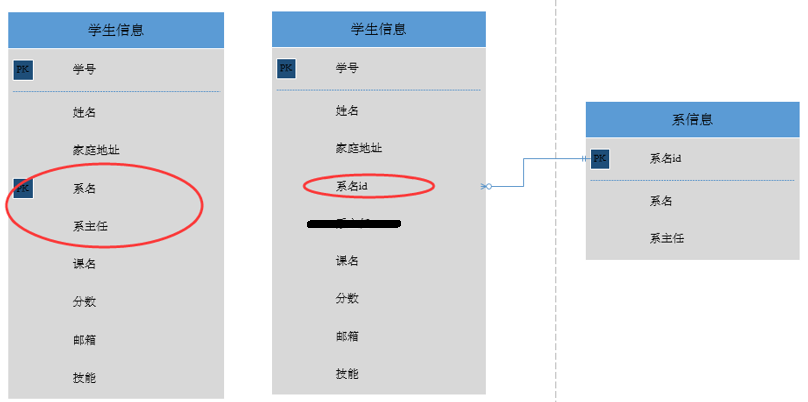
左边表的问题
- 数据冗余:每条记录都含有系名和系主任信息
- 删除异常:删除所有学生信息, 系信息也全部没了
- 插入异常:还没有招学生, 系信息就没法存进去
- 更新异常:系信息修改, 所有的学生信息都要进行修改
解释
上面的左边的表, 系名和学号组成码, 系主任由系名决定, 但是并不由学号来决定,所以是不符合第二范式的,右边的表在表一的基础上改进, 新建了一个表,将系的信息单独存起来,解决左边表的问题
第三范式
标准解释:消除非主属性之间的依赖关系,只保留非主属性与码的依赖关系
通俗解释:非主键列必须直接依赖于主键,不能存在传递依赖。即不能存在:非主键列 A 依赖于非主键列 B,非主键列 B 依赖于主键的情况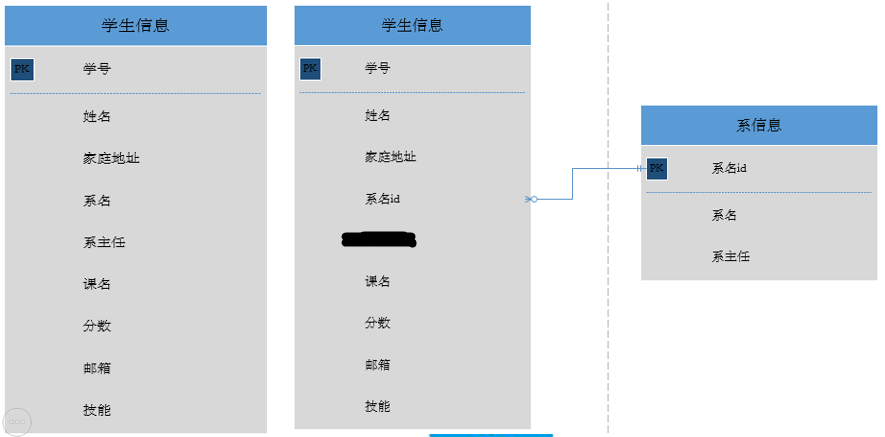
这个表很熟悉对吧, 只是系名不是主键, 也就是码只有一个属性,所以是符合第二范式的
但是: 非主属性’系主任’依赖于非主属性’系名’, 而非主属性’系名’又依赖于主键’学号’,所以不符合第三范式
解决办法
就是拆分表, 将系信息单独拿出来, 也就是右边的表
BC范式
标准解释: 一个表只有一个候选键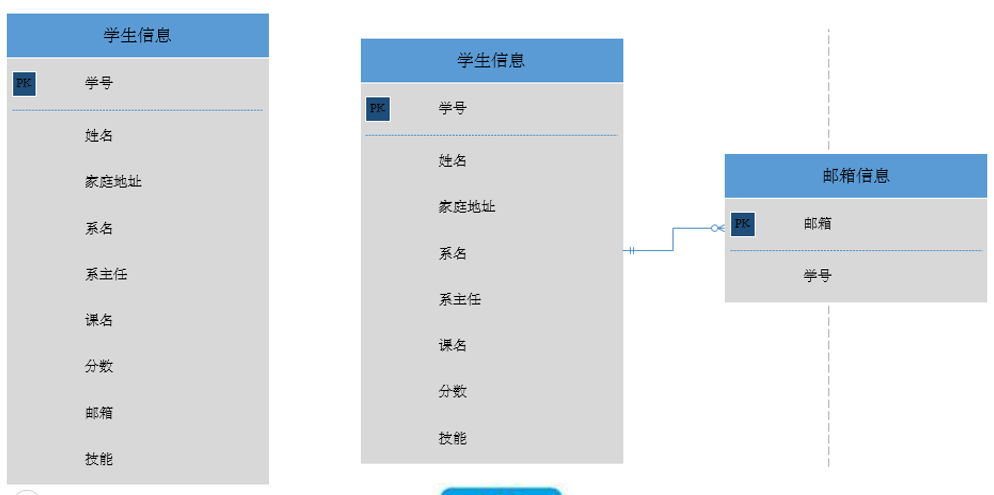
左边表的问题
学生信息表中, 学号和邮箱都是唯一的, 所以不符合BC范式
解决方案
将多个候选键拆分到不同的表
第四范式
消除表中的多值依赖,减少维护数据一致性的工作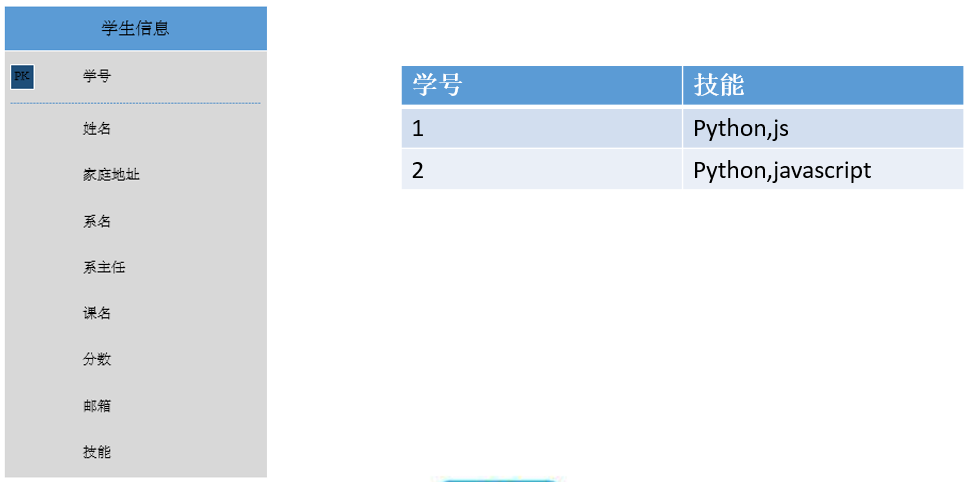
上面表的问题
一个学生有多项技能, 我们把它的技能都写到一个字段里面,技能是存在多个值的, 可能造成数据不一致, 比如js和javascript都是同一个, 但是却出现在不同的行中
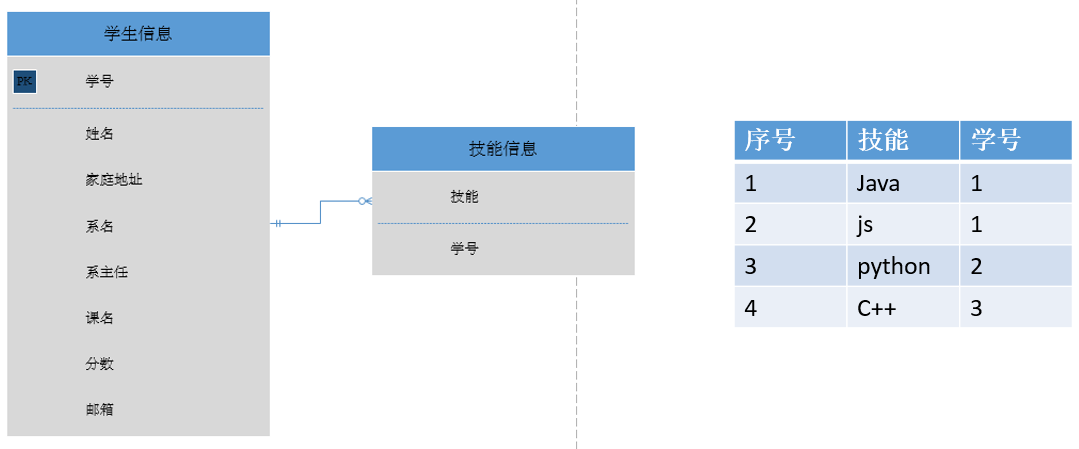
解决办法
将技能单独做成一个表(如上面第二个图)
反范式
我们一般都是遵从范式来构建我们的表, 但是有的时候正好相反, 设计出一个违背范式的表出来, 这就是反范式
场景
拿上面的’学生信息’和’邮箱信息’来说当我们的数据量非常大,前端要查询我们的表数据(一个学生的信息), 如果按照传统的范式来设计表, 我们要对先对’学生信息’按照姓名查询, 然后再到’邮箱信息’按照学号查询出邮箱,这就是两个操作, 当我们的数据达到好几亿的级别, 第二个操作无疑是影响性能的,所以游标的表就不符合要求, 反而左边的表在这种场景更加合理
总结
我们一般在设计表的时候, 并没有按照范式的定义来对照设置表, 二是根据自己的经验, 以及当前的生产环境来决定表的设计, 这样才是合理的, 范式只是标准, 当具体应用场景才是最终设计的决定因素