什么是Elasticsearch?
先说Elasticsearch的文件存储,Elasticsearch是面向文档型数据库,一条数据在这里就是一个文档,用JSON作为文档序列化的格式1
2
3
4
5
6
7
8{
"name" : "John",
"sex" : "Male",
"age" : 25,
"birthDate": "1990/05/01",
"about" : "I love to go rock climbing",
"interests": [ "sports", "music" ]
}
根据官网自己的介绍,Elasticsearch是一个分布式搜索服务,提供Restful API,底层基于Lucene,采用多shard的方式保证数据安全,并且提供自动resharding的功能
对于Elasticsearch,如果要在项目中使用,需要解决如下问题:
- 索引,对于需要搜索的数据,如何建立合适的索引,还需要根据特定的语言使用不同的analyzer等。
- 搜索,Elasticsearch提供了非常强大的搜索功能,如何写出高效的搜索语句?
- 数据源,我们所有的数据是存放到MySQL的,MySQL是唯一数据源,如何将MySQL的数据导入到Elasticsearch?
lucene
Elasticsearch底层是基于Lucene:
- Document:用来索引和搜索的主要数据源,包含一个或者多个Field,而这些Field则包含我们跟Lucene交互的数据
- Field:Document的一个组成部分,有两个部分组成,name和value。
- Term:不可分割的单词,搜索最小单元。
- Token:一个Term呈现方式,包含这个Term的内容,在文档中的起始位置,以及类型。
Lucene使用Inverted index来存储term在document中位置的映射关系。
譬如如下文档:
Elasticsearch Server 1.0 (document 1)
Mastring Elasticsearch (document 2)
Apache Solr 4 Cookbook (document 3)
使用inverted index存储,一个简单地映射关系: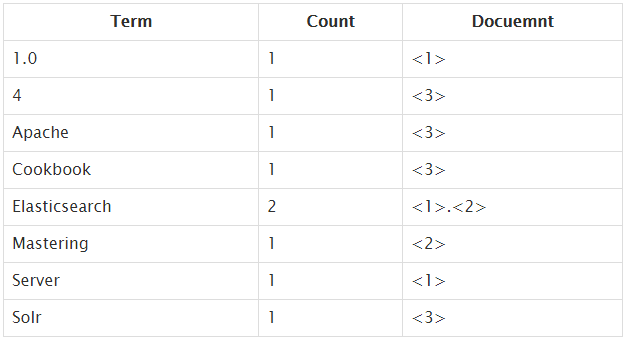
ES相关概念
数据层
- Index:Elasticsearch用来存储数据的逻辑区域,它类似于关系型数据库中的db概念。一个index可以在一个或者多个shard上面,同时一个shard也可能会有多个replicas。
- Document:Elasticsearch里面存储的实体数据,类似于关系数据中一个table里面的一行数据。
document由多个field组成,不同的document里面同名的field一定具有相同的类型。document里面field可以重复出现,也就是一个field会有多个值,即multivalued。 - Document type:为了查询需要,一个index可能会有多种document,也就是document type,但需要注意,不同document里面同名的field一定要是相同类型的。
- Mapping:存储field的相关映射信息,不同document type会有不同的mapping。
对于熟悉MySQL的童鞋,我们只需要大概认为Index就是一个db,document就是一行数据,field就是table的column,mapping就是table的定义,而document type就是一个table就可以了。
Document type这个概念其实最开始也把笔者给弄糊涂了,其实它就是为了更好的查询,举个简单的例子,一个index,可能一部分数据我们想使用一种查询方式,而另一部分数据我们想使用另一种查询方式,于是就有了两种type了。
服务层
- Node: 一个server实例。
- Cluster:多个node组成cluster。
- Shard:数据分片,一个index可能会存在于多个shards,不同shards可能在不同nodes。
- Replica:shard的备份,有一个primary shard,其余的叫做replica shards。
Restful API
Elasticsearch提供了Restful API,使用json格式,这使得它非常利于与外部交互,虽然Elasticsearch的客户端很多,但笔者仍然很容易的就写出了一个简易客户端用于项目中,再次印证了Elasticsearch的使用真心很容易。
Restful的接口很简单,一个url表示一个特定的资源,譬如/blog/article/1,就表示一个index为blog,type为aritcle,id为1的document。
而我们使用http标准method来操作这些资源,POST新增,PUT更新,GET获取,DELETE删除,HEAD判断是否存在。
综合
我们首先要做的是存储员工数据,每个文档代表一个员工。在Elasticsearch中存储数据的行为就叫做索引(indexing),不过在索引之前,我们需要明确数据应该存储在哪里。
在Elasticsearch中,文档归属于一种类型(type),而这些类型存在于索引(index)中,我们可以画一些简单的对比图来类比传统关系型数据库:
Relational DB -> Databases -> Tables -> Rows -> Columns
Elasticsearch -> Indices -> Types -> Documents -> Fields
Elasticsearch集群可以包含多个索引(indices)(数据库),每一个索引可以包含多个类型(types)(表),每一个类型包含多个文档(documents)(行),然后每个文档包含多个字段(Fields)(列)。
「索引」含义的区分
你可能已经注意到索引(index)这个词在Elasticsearch中有着不同的含义,所以有必要在此做一下区分:
- 索引(名词) 如上文所述,一个索引(index)就像是传统关系数据库中的数据库,它是相关文档存储的地方,index的复数是indices 或indexes。
- 索引(动词) 「索引一个文档」表示把一个文档存储到索引(名词)里,以便它可以被检索或者查询。这很像SQL中的INSERT关键字,差别是,如果文档已经存在,新的文档将覆盖旧的文档。
- 倒排索引 传统数据库为特定列增加一个索引,例如B-Tree索引来加速检索。Elasticsearch和Lucene使用一种叫做倒排索引(inverted index)的数据结构来达到相同目的。
- 默认情况下,文档中的所有字段都会被索引(拥有一个倒排索引),只有这样他们才是可被搜索的。