目录
[TOC]
前言
scrapy现在已经在我们的”雅典娜”系统中使用, 它是一个开源的由python编写的成熟的爬虫框架, git地址scrapy
需要掌握的技术和工具
- 爬虫相关知识(爬虫反爬虫)
- xpath语法, css选择器语法
- scrapy
- Bloom Filter
- python-rq
- redis或mongodb
安装scrapy
这里在ubuntu上安装
- 首先安装python, 版本2.7.3
sudo apt-get install python-devsudo apt-get install libevent-devpip install Scrapy
下面是在windows 64上安装scrapy的教程[python]Win7 X64安装python Scrapy
入门案例: 从w3school.com.cn开始
- 建立项目:
scrapy startproject w3school 编写Item: 编辑items.py, 对抓取的数据进行结构化
1
2
3
4
5
6
7
8
9
10import scrapy
from scrapy.item import Item,Field
class W3SchoolItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = Field()
link = Field()
desc = Field()编写pipelines.py: 主要完成数据的查重、丢弃,验证item中数据,将得到的item数据保存等工作
1
2
3
4
5
6
7
8
9
10
11
12
13import json
import codecs
class W3SchoolPipeline(object):
def __init__(self):
self.file = codecs.open('w3school_data_utf8.json', 'wb', encoding='utf-8')
def process_item(self, item, spider):
line = json.dumps(dict(item)) + '\n'
# print line
self.file.write(line.decode("unicode_escape"))
return itemsettings.py 开启piplines
1
2
3ITEM_PIPELINES = {
'w3school.pipelines.W3SchoolPipeline':300
}编写爬虫: 在spiders文件夹下新建: w3cshool_spider.py
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43#!/usr/bin/python
# -*- coding:utf-8 -*-
from scrapy.spider import Spider
from scrapy.selector import Selector
from scrapy import log
from w3school.items import W3schoolItem
class W3schoolSpider(Spider):
"""爬取w3school标签"""
#log.start("log",loglevel='INFO')
name = "w3school"
allowed_domains = ["w3school.com.cn"]
start_urls = [
"http://www.w3school.com.cn/xml/xml_syntax.asp"
]
def parse(self, response):
sel = Selector(response)
sites = sel.xpath('//div[@id="navsecond"]/div[@id="course"]/ul[1]/li')
items = []
for site in sites:
item = W3schoolItem()
title = site.xpath('a/text()').extract()
link = site.xpath('a/@href').extract()
desc = site.xpath('a/@title').extract()
item['title'] = [t.encode('utf-8') for t in title]
item['link'] = [l.encode('utf-8') for l in link]
item['desc'] = [d.encode('utf-8') for d in desc]
items.append(item)
#记录
log.msg("Appending item...",level='INFO')
log.msg("Append done.",level='INFO')
return items执行爬虫
scrapy crawl w3school --set LOG_FILE=log
Scrapy核心架构与代码运行分析
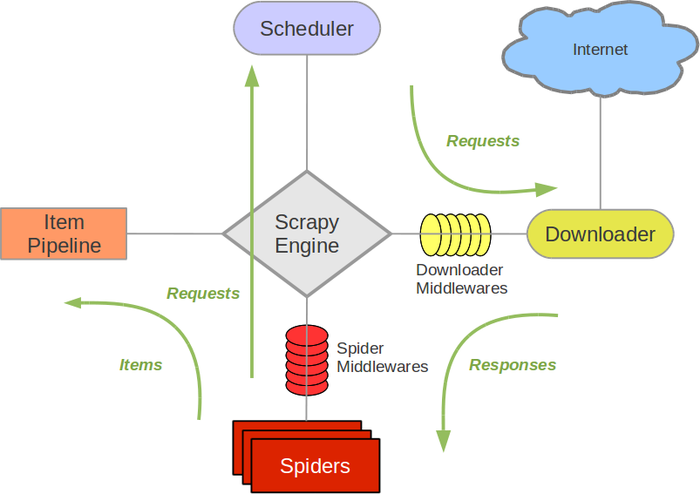
这个是官网的scrapy框架图, 介绍的很详细1
2
3
4
5
6
7
81. 引擎(Scrapy Engine),用来处理整个系统的数据流处理,触发事务。
2. 调度器(Scheduler),用来接受引擎发过来的请求,压入队列中,并在引擎再次请求的时候返回。
3. 下载器(Downloader),用于下载网页内容,并将网页内容返回给蜘蛛。
4. 蜘蛛(Spiders),蜘蛛是主要干活的,用它来制订特定域名或网页的解析规则。编写用于分析response并提取item(即获取到的item)或额外跟进的URL的类。 每个spider负责处理一个特定(或一些)网站。
5. 项目管道(Item Pipeline),负责处理有蜘蛛从网页中抽取的项目,他的主要任务是清晰、验证和存储数据。当页面被蜘蛛解析后,将被发送到项目管道,并经过几个特定的次序处理数据。
6. 下载器中间件(Downloader Middlewares),位于Scrapy引擎和下载器之间的钩子框架,主要是处理Scrapy引擎与下载器之间的请求及响应。
7. 蜘蛛中间件(Spider Middlewares),介于Scrapy引擎和蜘蛛之间的钩子框架,主要工作是处理蜘蛛的响应输入和请求输出。
8. 调度中间件(Scheduler Middlewares),介于Scrapy引擎和调度之间的中间件,从Scrapy引擎发送到调度的请求和响应。